昨天看到有小伙伴在我们游戏的 Lua 代码里写了一段判断中文的函数如下:
function M.is_chinese(c)
-- 参考Unicode编码表,http://www.chi2ko.com/tool/CJK.htm
if c >= 0x4E00 and c <= 0x9FA5 then
return true
end
return false
end
c 是通过 Lua 的 utf8.codes() 函数获得的值。根据 Lua 文档可以看出,对于 Lua 5.4 来说, utf8 库提供了 UTF-8 编码的一些支持,它只支持规范编码的 Unicode 字节流并且并不支持 surrogates 码点。关于 surrogates 不清楚的小伙伴可以看看 wtf-8。
Unicode & UTF-8
我们知道 Unicode 是现行的一种希望大一统的字符编码方式,最初的 1.0 版本设计的时候考虑不周,妄图用 2 个字节的长度来编码所有的字符,也就是 0x0000 - 0xFFFF,结果发现这是痴心妄想。于是之后又对最初的设计进行了不断的扩充,目前 Unicode 分成了 17 个平面,也就是 17 个码点范围,而最初的 0x0000 - 0xFFFF 也就是我们最常说的 BMP(Basic Multilingual Plane)。具体的平面划分可以参考这里 Unicode Planes。
设计好了字符码点之后,就需要设计对其的编码方式,其中 UTF-8 是对 Unicode 支持的最流行的编码,当然还有一些例如 UTF-16 的编码方式在 windows 世界跟 JavaScript 语言中被广泛使用。
UTF-8 编码是一种变长字节编码,详细可见 wiki,Unicode 码点跟 UTF-8 编码的相互转换规则如下图:

一个比较简单理解的例子比如编码 Unicode 码点(U+00E9)字符 é 它的 UTF-8 编码之后是:11000011 10101001
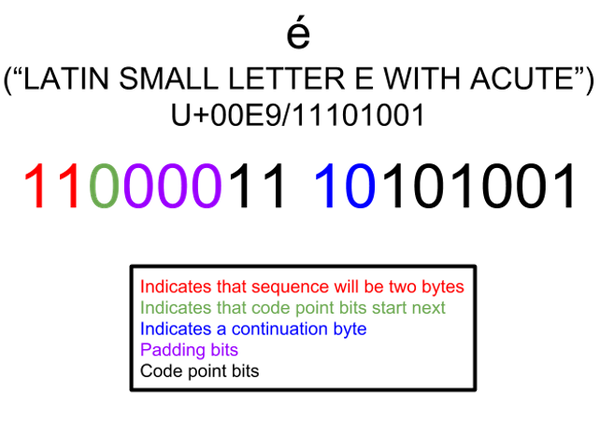
Lua 中 utf8.codes() 函数会遍历 UTF-8 字符并返回其对应的 Unicode 码点。所以小伙伴写的代码其实就是判断字符的 Unicode 的码点是否是中文。
中文判断
这就引起了我的兴趣。在 Unicode 的所有码点中,到底哪些是分配给中文汉字的呢?于是我查了一下 Unicode 的文档。最新的 Unicode 文档已经更新到 14.0 了 Unicode 14.0 Character Code Charts。
可以看到 Unicode 按照地球上的区域划分了不同的码点,并给不同的国家地区设计了不同的模块。我们最关心的当然是咱们的中文,也就是属于 East Asian Scripts 的 CJK Unified Ideographs 的部分以及其扩充。
对其进行深入阅读之后我发现,小伙伴写的检查其实只是所谓中文汉字的一个子集。Unicode 把东亚这边的文字统称为表意文字,跟他们西方的表音文字自然是不同的。而这些使用表意文字的国家主要是中国、日本、韩国、越南等等。所以最开始他们统称这样的字符为 CJK(Chinese, Japanese, and Korean),当然其实这个集合里面的字符远不止这三个国家的字符。
完整的范围
仔细阅读文档后我发现,如果真的想判断一个比较完整的汉字范围,可能需要如下范围判断:
最新最全的范围如下
CJK Unified Ideographs (4E00–9FFF) contains 20,992 characters
CJK Unified Ideographs Extension A (3400–4DBF) contains 6,592
CJK Unified Ideographs Extension B (20000–2A6DF) contains 42,720 characters
CJK Unified Ideographs Extension C (2A700–2B73F) contains 4,153 characters
CJK Unified Ideographs Extension D (2B740–2B81F) contains 222 characters
CJK Unified Ideographs Extension E (2B820–2CEAF) contains 5,762 characters
CJK Unified Ideographs Extension F (2CEB0–2EBEF) contains 7,473 characters
CJK Unified Ideographs Extension G (30000-3134F) containing 4,939 characters [Unicode 13.0]
CJK Compatibility Ideographs (F900–FAFF), only 12 characters: FA0E, FA0F, FA11, FA13, FA14, FA1F, FA21, FA23, FA24, FA27, FA28 and FA29
以下可以不判断,属于遗留的不建议范围
CJK Compatibility (3300–33FF)
CJK Compatibility Forms (FE30–FE4F)
CJK Compatibility Ideographs (F900–FAFF)
CJK Compatibility Ideographs Supplement (2F800–2FA1F)
当然,这么判断的内容就不仅仅是汉字了,而是所有表意文字的范围,也就是汉字的超集。具体可以查看 Unicode 文档或者 wiki CJK
CJK
接着我又开始好奇,这些字符是如何被 Unicode 收录的,于是我发现了一个叫 IRG 的组织,这个组织由中国、香港、澳门、新加坡、日本、韩国、朝鲜、台湾、越南以及 Unicode 联盟代表等人员构成。他们会接受来自各国东亚国家的申请,仔细审查评估 CJK 字符来决定是否纳入 Unicode 标准。
Unicode 还专门设计了一个 Unihan 数据库来帮助查询这些 CJK 字符 Unihan。
最后在浏览 CJK 字符的时候,我突然想到一个有意思的问题。我发现 Unicode 对于汉字的编码会既编码偏旁部首,又会直接编码汉字本身,这不是一种冗余设计吗?
关于这个问题,Unicode 也做了一下解释。
不用偏旁部首的组合方式来做类似汉字的编码,其实也包括日语不仅仅编码了平假、片假名一样。
主要原因是表意文字相当复杂,比如一个用偏旁部首组合成的字,偏旁部首在不同字中占据的比例是不一样的,所以很难通过只编码偏旁部首的方式来编码这样的文字。比如 “如” 这个字,由 “女” 和 “口” 组成,但是在 “如” 中,“口” 占据的比例跟他们在别的字可能不一样,比如 “吃”。 同样的,也存在相同的偏旁部首在不同的字中写法不同的情况,比如 “肝” 跟 “背” 。当然理论上可以给每种不同写法设计一个码点,但是这是相当困难的。
而且虽然目前加入的表意文字数量大大超过了 Unicode 最初的预期,在 25 年间编码了 80000 多个表意文字,相当于每年超过 3200 个,但是想填满 Unicode 所有码点,起码需要 250 年,而且目前大部分常用的表意文字已经被编码了,剩下的比较少,并且剩下大部分是变体,而且各国政府也在控制这些变体的数量。
Unicode 针对 CJK 的部分疑问也总结了一个页面来解答,感兴趣的可以仔细看看:FAQ Chinese and Japanese